Высоконагруженные приложения - Глава 6 - Партиционирование

Ранее книжный клуб нашей компании изучил отличную книгу:
Martin Kleppmann - Designing Data-Intensive Applications
Мартин Клеппман - Высоконагруженные приложения. Программирование, масштабирование, поддержка
Это - лучшая книга о создании комплексных масштабируемых программных систем, которые я когда-либо читал. 💪
Как обычно, я подготовил краткий обзор и майнд-мапу.
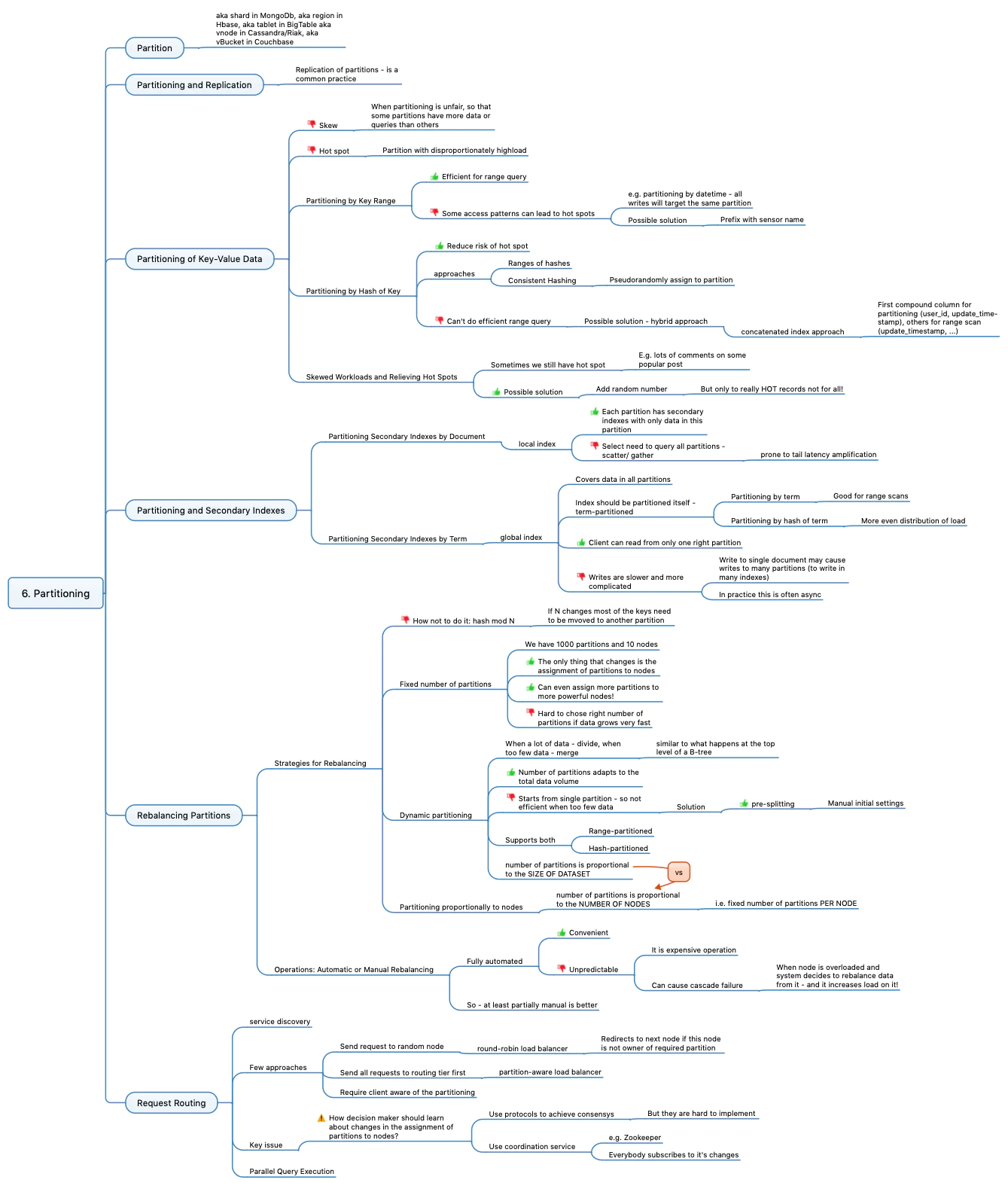
Глава 6 содержит все, что следует учитывать команде разработчиков при проектировании хранилища для больших данных:
- Партиция, она же шард, она же регион, он же tablet, она же vNode, она же vBucket. Это еще один подход к хранению данных в дополнение к Репликации (рассмотренной в предыдущей главе).
- Как партиционировать данные со структурой ключ-значение (первичный индекс). Проблемы с партиционированием - skew и hotspot. Подходы: диапазон ключа и хэш ключа.
- Партиционирование для вторичных индексов: локальный индекс и глобальный индекс
- Ребалансировка партиций по мере роста. Плохие и хорошие подходы, проблемы и способы их решения. Ручная и автоматическая перебалансировка.
- Маршрутизация запросов. Разные подходы, проблемы и решения.