Designing Data-Intensive Applications - Chapter 3 - Storage and Retrieval

Earlier this year the book club of our company has studied excellent book:
This is the best book I have read about building complex scalable software systems. 💪
As usually I prepared an overview and mind-map.
Chapter 3:
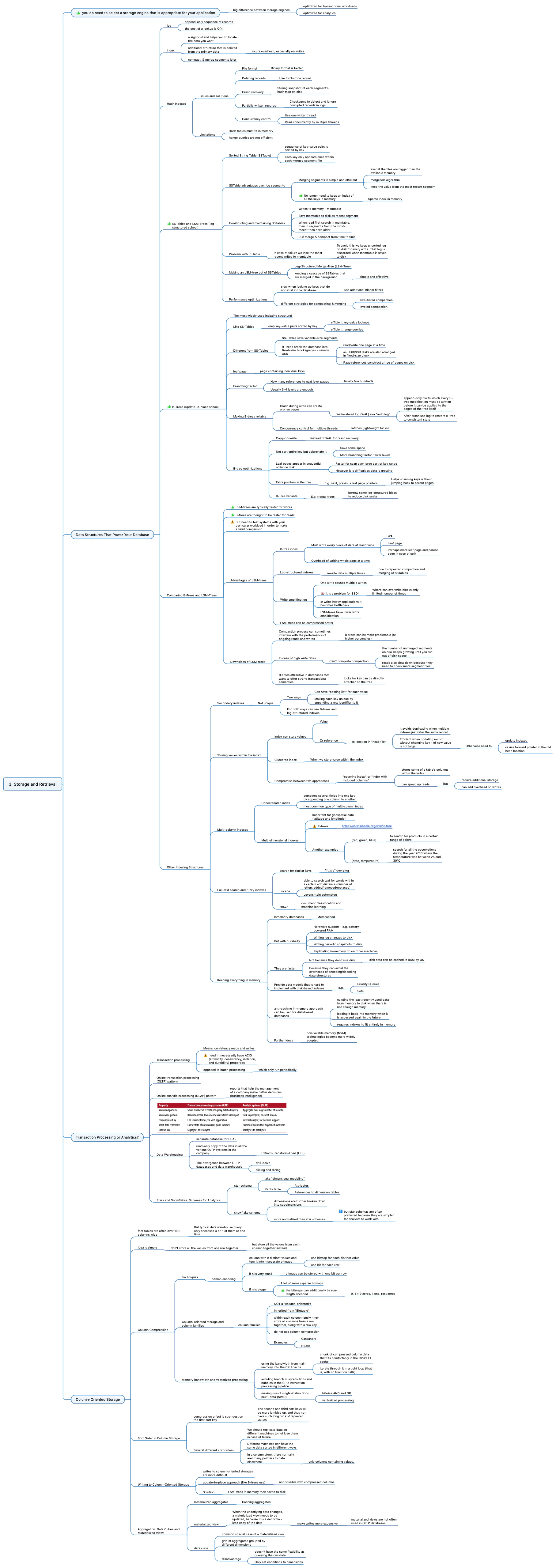
- Data structures:
- Log-structured. SSTables / LSM-trees (when we don’t update anything but write to the end). A very cool idea of how to store data.
- Sorted files.
- Indexes for each one.
- Moreover, the indexes can be created not for all the records, because they are sorted, and if the sizes of the records are the same, then the search between two known indexed records is a binary O(log n) search.
- We always write to the last file.
- The process of merging files is a school algo: how to write O(n) merge of two sorted arrays into one sorted array.
- Update-in-place. B trees (when we directly update records). Very smart too.
- Trees - a simpler idea, but here it is very interesting sub-idea with segments that are tuned for the work of disk drives - and hence the possible problems with SSDs due to many segment rewrites
- Log-structured. SSTables / LSM-trees (when we don’t update anything but write to the end). A very cool idea of how to store data.
- Indexing: primary, secondary, multi-column, full-text
- About indexes - it is obvious that miracles do not happen and additional structures are needed.
- Interestingly, sometimes values can be stored inside the indexes.
- Unfortunately, too few info about full-text search - it is interesting to learn more about it.
- OLTP vs OLAP. The clear separation of OLAP / OLTP is very interesting.
- Column-based storage.
- There is a very interesting aspect about data compression: how many zeros, then how many ones - a kind of compressor. This is possible only in memory - just for one next SSTable
Much more details in the mind-map:
See also:
- Designing Data-Intensive Applications - Chapter 5 - Replication
- Designing Data-Intensive Applications - Chapter 7 - Transactions
- Designing Data-Intensive Applications - Chapter 10 - Batch Processing
- Designing Data-Intensive Applications - Chapter 8 - The Trouble with Distributed Systems
- Designing Data-Intensive Applications - Chapter 4 - Encoding and Evolution