Designing Data-Intensive Applications - Chapter 6 - Partitioning

Earlier the book club of our company has studied excellent book:
This is the best book I have read about building complex scalable software systems. 💪
As usually I prepared an overview and mind-map.
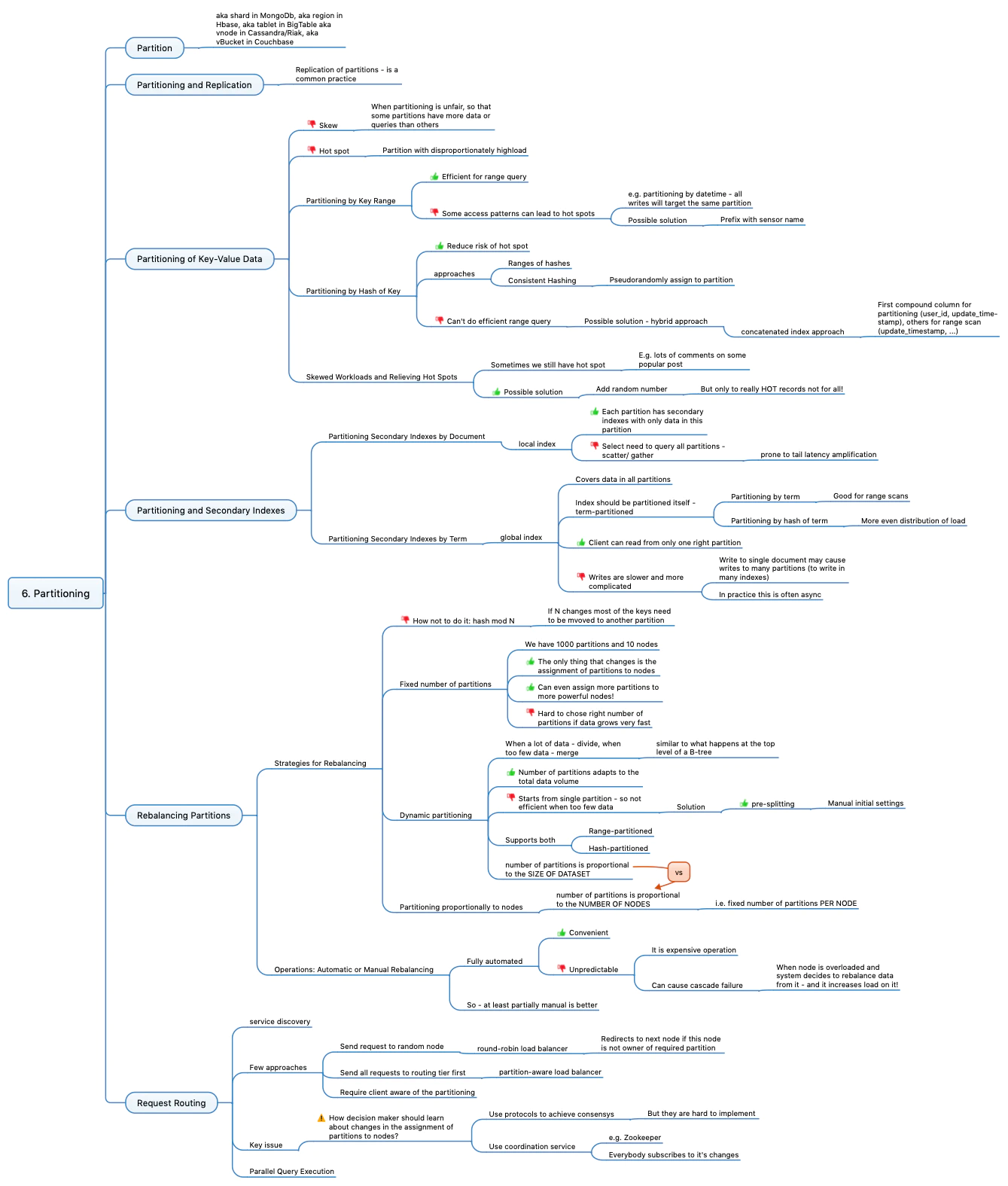
Chapter 6 contains everything the DEV team should consider when designing storage for big data:
- Partition aka Shard aka Region aka Tablet aka vNode aka vBucket. It is another approach for storing the data in addition to Replication (reviewed in the previous chapter)
- How to partition key-value data (primary index). Problems with partitioning - skew and hotspot. Approaches: key range and hash of key.
- Partitioning for secondary indexes: Local index and Global index
- Rebalancing partitions as you grow. Bad and good aproaches, problems and how to deal with them. Manual vs automated rebalancing.
- Request routing. Different aproaches, issues and solutions.
See also:
- Designing Data-Intensive Applications - Chapter 5 - Replication
- Designing Data-Intensive Applications - Chapter 10 - Batch Processing
- Designing Data-Intensive Applications - Chapter 9 - Consistency and Consensus
- Designing Data-Intensive Applications - Chapter 7 - Transactions
- Designing Data-Intensive Applications - Chapter 12 - The Future of Data Systems