Designing Data-Intensive Applications - Chapter 10 - Batch Processing

Earlier the book club of our company has studied excellent book:
This is the best book I have read about building complex scalable software systems. 💪
As usually I prepared an overview and mind-map.
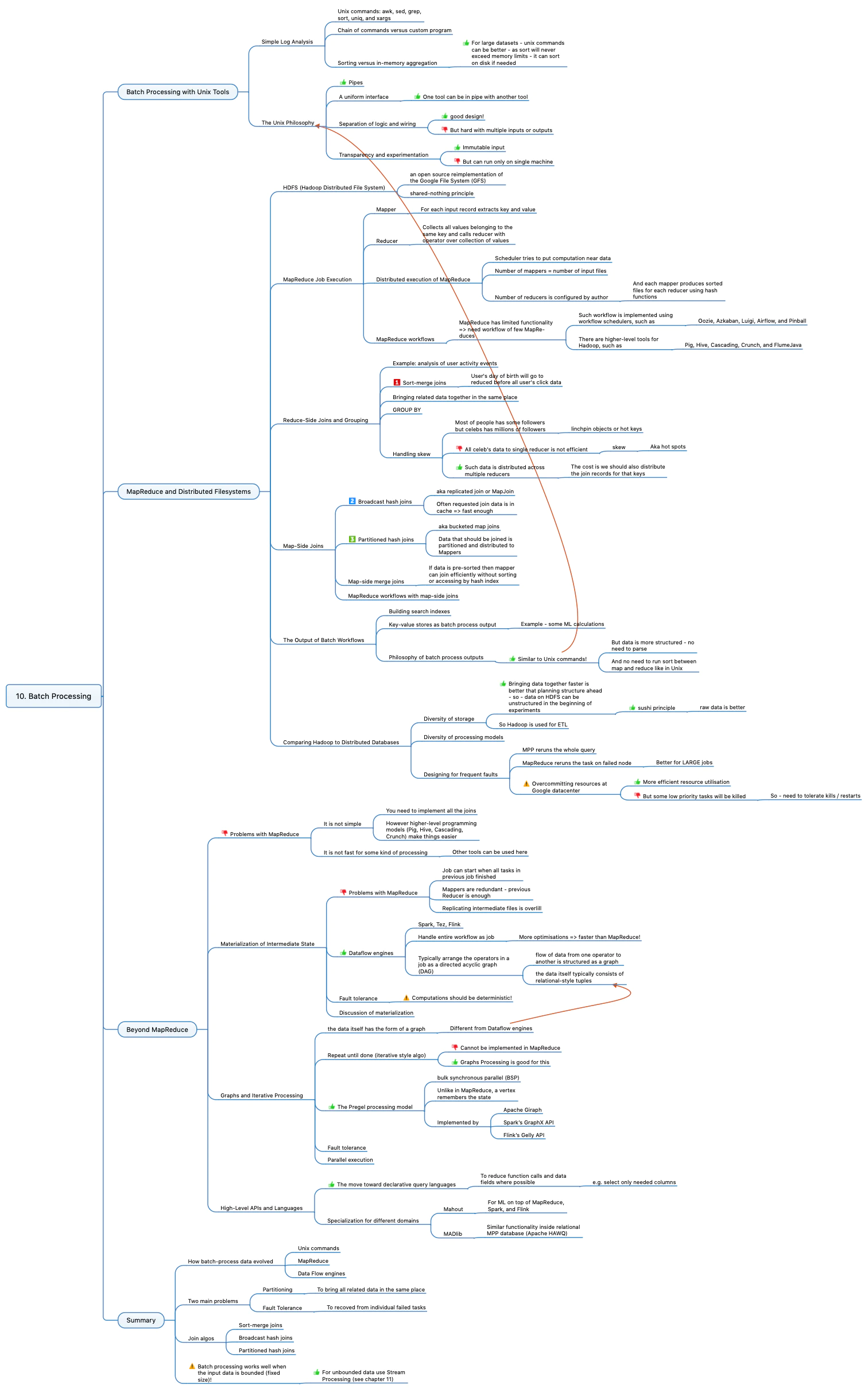
Chapter 10 discovers all aspects about big data Batch Processing. If your system needs to process some data then your DEV team should learn this info.
- Unix tools for batch processing and brilliant concept of pipes.
- MapReduce and Distribute File Systems. How this approach solves problems of Unix pipes. Fault Tolerance and Partitioning. Usage and implementations of Joins, Grouping, Mapping. Available tools and problems of this approach.
- What is beyond MapReduce. Dataflow engines, Graph processing, High-level APIs and MPP databases. Dealing with Fault Tolerance and Partitioning. Implementations, problems, what to use and when.
See also:
- Designing Data-Intensive Applications - Chapter 12 - The Future of Data Systems
- Designing Data-Intensive Applications - Chapter 2 - Data Models and Query Languages
- Designing Data-Intensive Applications - Chapter 11 - Stream Processing
- Designing Data-Intensive Applications - Chapter 7 - Transactions
- Designing Data-Intensive Applications - Chapter 6 - Partitioning