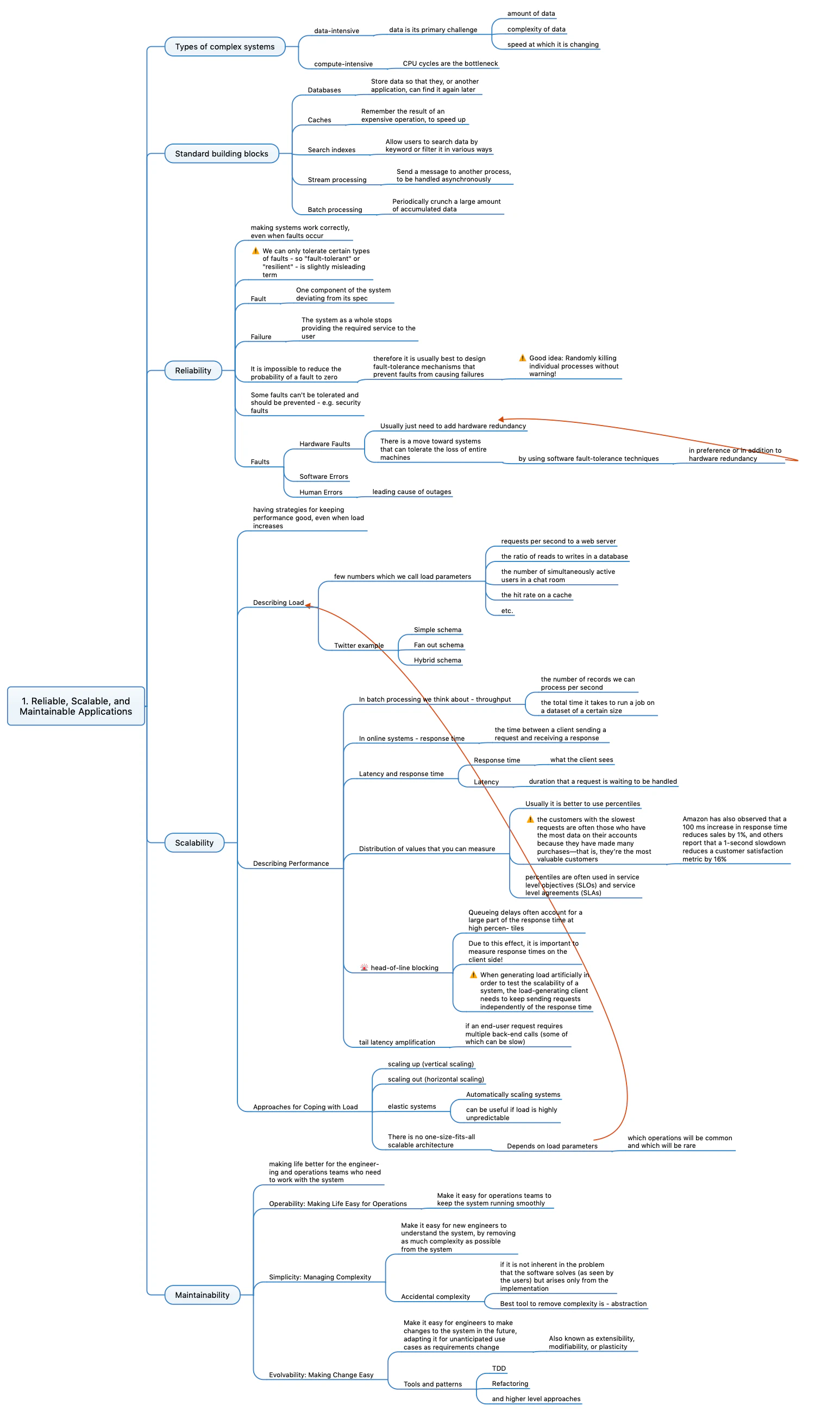
System Design Interview - Chapter 7 - Design a Unique ID Generator in Distributed Systems
Generating unique ID seems to be a simple task, but it is not in a high-load distributed systems!
This topic consists of:
- Understanding the requirements and why it is a complicated task
- Possible solutions:
- Multi-master replication
- Universally unique identifier (UUID)
- Ticket server
- Twitter SNOWFLAKE approach (seems to be the best one!)
- Details:
- Timestamp
- Sequence number
- Other issues
- Clock synchronization
- Section length tuning
- High availability
These items are disclosed in a very interesting Chapter 7 of the book: