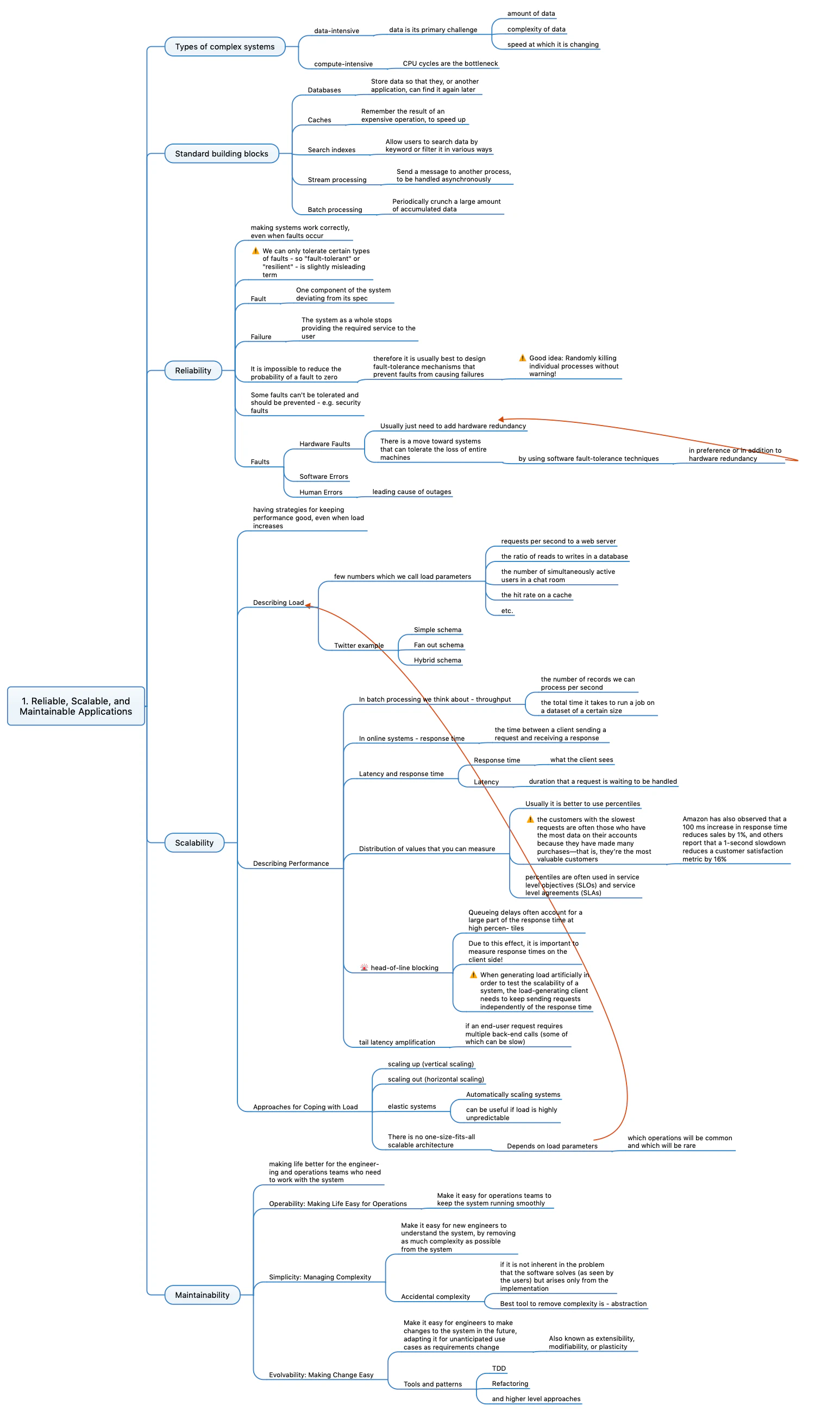
System Design Interview - Chapter 6 - Design a Key-Value store
Key-Value stores are the most basic but widely used data storages.
Design of key-value store consists of understanding the following topics:
- What do we want from key-value store?
- Single server key-value store
- DISTRIBUTED key-value store:
- CAP theorem
- Real-world trade-offs for distributed systems
- System components:
- Data partition
- Data replication
- Consistency
- Inconsistency resolution: Versioning
- Handling all types of failures: Failure detection, Handling TEMPORARY failures, Handling PERMANENT failures, Handling data center outage
- System architecture diagram
- Write path
- Read path
These items are disclosed in a very interesting Chapter 6 of the book: